 记录本
记录本SQL查询执行顺序实例
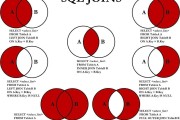
一、SQL查询执行顺序 FROM/JOIN:首先确定要从哪些表中获取数据,以及这些表之间是如何连接的。如果使用了JOIN,则需要确定连接的类型(如INNER JOIN、LEFT JOIN等)和连接条件。 ON:对JOIN操作中的连接条件进行过滤,以获取符合条件的记录。这一步通常在FROM/JOIN之后立即执行。 WHERE:对FROM/JOIN和ON过滤后的数据进行进一步的筛选,只保留满足WHERE条件的记录。 GROUP BY:将WHERE过滤后的数据按照指定的列进行分组。分组操作会生成一个新的虚拟表,其中每个组包含一组具有相同值的记录。 HAVING:对GROUP BY分组后的数据进行过滤,只保留满足HAVING条件的组。HAVING通常用于对聚合函数的结果进行筛选。 SELECT:从GROUP BY和HAVING过滤后的数据中选择需要返回的列。如果使用了聚合函数(如COUNT、SUM等),则这些函数会在这一步进行计算。此外,如果查询中包含了DISTINCT关键字,则会在这一步对数据进行去重处理。 ORDER BY:对SELECT返回的数据按照指定的列进行排序。排序可以是升序(ASC)或降序(DESC)。 LIMIT:对排序后的数据进行分页处理,只返回指定数量的记录。LIMIT子句通常用于实现分页查询。 二、具体实例 假设有两张表:用户表(user)和订单表(orders),结构如下: 用户表(user):包含用户ID(user_id)、用户名(user_name)和城市(city)等字段。 订单表(orders):包含订单ID(order_id)和用户ID(user_id)等字段。 现在,我们希望查询来自“北京”且订单数少于2的用户,并按订单数降序排列。SQL查询语句如下: SELECT a.user_id, a.user_name, COUNT(b.order_id) AS total_orders FROM user AS a LEFT JOIN orders AS b ON a.user_id = b.user_id WHERE a.city = '北京' GROUP BY a.user_id, a.user_name HAVING COUNT(b.order_id) < 2 ORDER BY total_orders DESC LIMIT 10; 三、执行过程分析 FROM/JOIN:从用户表(user)和订单表(orders)中进行LEFT JOIN操作,连接条件是a.user_id = b.user_id。 ON:应用连接条件a.user_id = b.user_id进行过滤,得到符合条件的记录。 WHERE:对连接后的数据进行筛选,只保留城市为“北京”的记录。 GROUP BY:将筛选后的数据按照用户ID(a.user_id)和用户名(a.user_name)进行分组。 HAVING:对分组后的数据进行过滤,只保留订单数少于2的组。 SELECT:从分组和过滤后的数据中选择用户ID(a.user_id)、用户名(a.user_name)和订单数(COUNT(b.order_id) AS total_orders)作为返回结果。 ORDER BY:对返回的结果按照订单数(total_orders)进行降序排列。 LIMIT:对排序后的结果进行分页处理,只返回前10条记录。 通过以上分析,我们可以清晰地看到SQL查询的执行顺序以及每个步骤的作用。理解这些步骤有助于我们更好地优化SQL查询,提高查询性能。
版权声明
本文仅代表作者观点。
本文系作者授权发表,未经许可,不得转载。
上一篇:Python注册,按钮直接执行SQL语句 下一篇:SQL创建视图
相关文章


作者文章
- 2025-01-12阶段总结 3周前 (01-12)
- 写在2024的尾巴上 1个月前 (12-31)
- c# WPF开发erp逻辑梳理 1个月前 (12-25)
- 杂记规划 2个月前 (12-11)
- 【转载】从零开始入门数据分析-SQL篇 2个月前 (12-05)
发表评论:
◎欢迎参与讨论,请在这里发表您的看法、交流您的观点。